Indieweb: POSSE using Eleventy and Netlify Functions
“POSSE”: Publish on your Own Site, Syndicate Elsewhere #
POSSE is an abbreviation for Publish (on your) Own Site, Syndicate Elsewhere, the practice of posting content on your own site first, then publishing copies or sharing links to third parties (like social media silos) with original post links to provide viewers a path to directly interacting with your content.
I’ve briefly mentioned POSSE at How Would I Extend Virga? and I’ve implemented “auto tweet posing when I deploy new article” by following Max Böck’s tutorial.
While Max Böck’s tutorial is great, I’ve been thinking about changing and exploring a few details.
What details I want to explore that comes to my mind right now:
- Add unit tests to the implementation
- What can Netlify Dev do for helping develop “Functions”?
- Try new package for Twitter library
And this is where my journey begins.
This is a story about achieving POSSE practice using Eleventy and Netlify Functions and along its way, I want to visit unit testing, Netlify Dev and new (hopefully better maintained) Twitter library for API.
Again, I really appreciate for Max Böck for sharing a tutorial on this.
IF new article was deployed THEN tweet title and URL of the article #
In an essence, this is what I’m trying to do and everything can be done using Netlify Functions.
In order to accomplish this, I would need to get the title and URL of the article.
This shouldn’t be difficult since Eleventy gives me many ways to access contents data.
However…
Netlify Functions aren’t part of Eleventy, so where and how do I get contents? #
.
├── 11ty # ⇒ This is input dir for Eleventy
├── dist # ⇒ This is output dir for Eleventy
├── functions # ⇒ This is for Netlify Functions
├── .eleventy.js
└── README.mdI suppose I could move functions/ directory into 11ty/ so I can use contents data for tweets from Eleventy.
But I’ve decided to use the JSON Feed as the input for Netlify Functions.
The JSON Feed is a syndication format, like RSS and Atom, but with one exception: it’s JSON instead of XML.
This is my JSON Feed(You can subscribe it with Feedbin or Feedly and I’m sure other RSS services support it.)
The JSON Feed has all the data I need for a tweet, I don’t see why not using it.
Trigger a synchronous serverless function on deploy-succeeded events #
I need trigger serverless function calls when certain Netlify events happen. Netlify does allow me doing this.
to trigger a synchronous serverless function on deploy-succeeded events, name the function file
deploy-succeeded.jsordeploy-succeeded.go.
This is exactly what I’m looking for. This means that I need to save a deploy-succeeded.js at functions/ directory.
According to “Synchronous function format” from Netlify Doc I need to export a handler method with async.
exports.handler = async () => {
// 1. Fetch the JSON Feed
// 2. Process that info so that I can tweet
};Test Driven Developing deploy-succeeded.js #
For me, TDD is far more than a safety net. It’s also constant, fast, realtime feedback. Instant gratification when I get it right. Instant, descriptive bug report when I get it wrong.
I did implement deploy-succeeded.js already, I’ll delete it and try TDD(Test Driven Development).
A couple of questions I have before start doing TDD:
- I don’t want to actually send out a tweet every time I run test. I need to mock it
- How I’m going to test functions that would go inside the
handlermethod?
For mocking, I’ll use Mock Service Worker which “is an API mocking library that uses Service Worker API to intercept actual requests.” It sounds like for client-side only, but it actually works in Node.js too.
For testing non-export functions, I’ve decided to use jhnns /rewire. This looks like very black magic. I could export functions that I’m going to write for test, but that’s not what I intended to do with deploy-succeeded.js so I’ll take the black magic this time.
Experimenting is fun.
Let’s CDD before TDD #
I like Comment Driven Development(CDD).
An empty white page is a mirror into your mind. When the ideas in your mind are clouded, so are the words on the page in front of you. Re-writing is re-thinking. It’s the single best way to sharpen your ideas.
I’m not smart. I don’t have CS degree. But I love writing. I just don’t pick and choose what language I write. Just like on this blog, I write in English (pardon me writing poorly), I usually write things in Japanese. I’m fluent in HTML and CSS, but not so much in JavaScript.
But an important thing which still keep me working on Web development is: I love writing.
So whenever I work on programming stuff, I write comment first.
It’s frightening for me to looking a blank empty white page. This is why I like the dark theme. The dark theme makes me feel a little safer.
I write comments because it takes time to clarify what I want my code to do.
I want to my ideas to be as clear as a Neiman Marcus mirror as David Perell said before writing any codes.
// Require libraries
// Configure libraries
// Fetch JSON Feed
// Test if the most recent item in feed should be tweeted
// Create a text for a tweet. Remember there is 280 characters limit on Twitter
// Post a tweet
// Lambda Function Handler
exports.handler = async () => {};My first rough draft would look like this. Even though Jeff Bezos might not approve, I like writing in bullet lists.
Let’s dig a bit deeper using an example.
How should I go about addressing this idea?: “Test if the most recent item in feed should be tweeted”
Finding the most recent item in feed is easy since JSON Feed has an “items” as an array so items[0] should be the most recent item.
However, what is the criteria for deciding an item “should be tweeted”?
I can tell by reading the comment that I’d need more research for that part. It’s too vague.
Just like writing an essay, I need find out something to rely on.
For this case, I think the Inversion Principle would help me.
What don’t I want to tweet? How can I avoid the same tweet appearing on my Twitter stream? How can I tell that I’ve already tweeted for the article which I just fixed typos?
The answers for those questions are in Twitter API document because I need to find out how the search in Twitter works.
I write comments like this. My rough draft becomes an outline, and an outline will become headings then questions and answers thrive in that headings.
I don’t commit them so nobody gets to read it but this is what I meant for writing helps me clarify my ideas.
TDD is a validator of my expression #
Unfortunately, I don’t yet to know how GPT-3 works, but I don’t think even GPT-3 cannot generate JavaScript expressing my idea. (Well, maybe it does, but I don’t know)
Therefore, I need a validator to ensure that I expressed what I want correctly for now.
After researching Tweeter API Doc, I did find out about the search feature. In short, “the Twitter Search API searches against a sampling of recent Tweets published in the past 7 days.”
If I were simply used the Search API to find out I tweeted the article or now by searching article URL which I think it’s unique enough for this kind of search, then there would be a couple of issues.
The issues I can see now would be situation like this: if I did tweet the most recent article but after 7 days, I’ve noticed typos, so I fix them and deploy it, then that article is still the most recent article, and it’ll be after 7 days, so the article will get tweeted again.
I can’t speak for the others but for me, Twitter is already noisy, so it would be great if I can avoid being the noise…
Again, the Inversion Principle works here.
Which will lead me: How can I prevent hitting Search API if the article is more than 7 days old?
Let’s invert again, so it would sound more natural: If the most recent article is less than 7 days old, let’s hit Search API to make sure it’s not in Twitter yet.
Doesn’t this sound like a function?
It does to me, so I write a test for it.
test('The most recent post is LESS than 7 days old', () => {
// Arrange
advanceTo(new Date(2021, 0, 1, 0, 0, 0));
const now = new Date();
const morethan7days = '2021-01-10T12:15:31.627Z';
const lessthan7days = '2021-01-06T12:15:31.627Z';
// Assert
expect(isLessThan7DaysOld(now, morethan7days)).toBe(false);
expect(isLessThan7DaysOld(now, lessthan7days)).toBe(true);
});And write the function.
const isLessThan7DaysOld = (now, compare) => {
return Math.ceil((now - new Date(compare)) / 1000 / 60 / 60 / 24) >= -7;
};Does Mock Service Worker live up my expectation? #
Next, I need to find out if my latest article’s URL is in the Twitter Search API or not.
I have to manipulate the response from Search API for this. Well, technically, I could use fake URL as a query to get “Not found” response and real URL to get “found” one, but 1) GET is safer to experimenting and 2) I want to avoid flakiness in my tests.
Importantly, I want to try out Mock Service Worker.
Whenever I experiment a new tool for the first time, I start by making an isolated environment for it. So I have a dedicated directory for this kind of work. The benefits of doing this is that it’s safe and clean, meaning I don’t have to worry about muddying the ongoing project, and I have a central place to look up how actually things work.
Mock Service Worker has a great document helping me set it up, and I did create an example using a publicly available API (means that I don’t have to go through Auth process to GET responses).
I don’t exactly know how this thing works, but I know how to make it works for me.
My initial test against this function looked like this:
test('Twitter Search API returns ZERO result', async () => {
// Arrange
const query = 'TEST';
// Act
const actual = await doesSearchReturnZero(query);
// Assert
expect(actual).toBe(true);
});But, I soon realized this doesn’t add any value as a test since I’ve mocked response from https://api.twitter.com/1.1/search/tweets.json to always return [].
Eliel Saarinen, a finnish-American architect once said:
Always design a thing by considering it in its next larger context – a chair in a room, a room in a house, a house in an environment, an environment in a city plan.
Whenever I face the situation like this, I always come back to his quote and always remind me what I’m intended to do originally.
I want to design a gateway. This gateway will stop the process when criteria have met. Before thinking about designing this gateway, I need to think about more detail about the next action.
However, I’ve learned what to do with Mock Service Worker.
Realizing via visualizing #
My next action, according to my initial outline is: “Create a text for a tweet. Remember there are 240 characters limit on Twitter”.
I’ve decided to go with this simple format: ${title} via ${siteTitle}: ${url} and I need get those from the JSON Feed.
Let’s get it visualized.
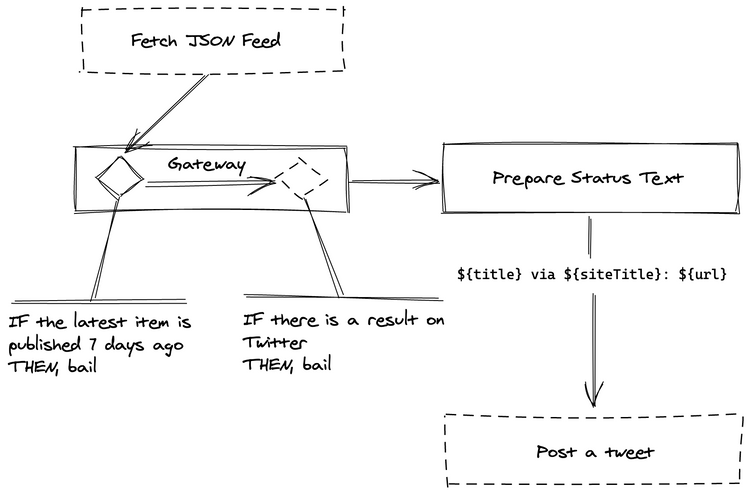
Dashed boxes on Fig 1 are ones that need to be mocked and now I can see the whole picture, I should go ahead work on “Prepare Status Text”.
test('Prepare a status text for a tweet', () => {
// Arrange
const ingredient = {
status: 'This is a test tweet with in 240 characters limit',
url: 'https://virga.frontendweekly.tokyo/test-',
siteName: 'Virga',
};
// Act
const actual = prepareStatusText(ingredient);
// Assert
const expected =
'This is a test tweet with in 240 characters limit via Virga: https://virga.frontendweekly.tokyo/test-';
expect(actual).toEqual(expected);
});Based on my visualization, I’d say this is the most complicated part of all, and it’s not too difficult to do. (I’m assuming URL is 40 characters, by the way.)
prepareStatusText() would be only test that have value, but I’m going to add mocks for “Fetch JSON Feed” and “Post a tweet”, too.
Back to mostly empty state #
At this point, I’d have sufficient tests, so I’ll delete most of my implementation.
Well, I don’t literally delete it, but I put them away from the editor. Then try to remember what I had written and generate new implementation from the memory.
I’m not smart, but I still can use my memory as a filter, removing excessive and organizing what is vital.
My unit tests are there to guide me where I’m going.
I don’t have to do this every time, but I do this often. I really like the part where I delete the implementation. This helps me think and remember. I might end up with the same lines of codes, but that’s ok. Some will say, it’s wast of time. Sure, I don’t disagree with it at all.
But having a good feedback cycle helps me grow. And I believe feedbacks are not just from someone else. When a feedback comes from myself, that may be called a reflection, but the concept is same.
Writing is writing #
I love writing. I don’t discriminate what language I write. HTML, CSS and JavaScript are languages that I’ve learned and use. (I don’t speak them, but I do read them, sometimes just for fun.)
Writing is writing. It shouldn’t be matter what language I’m writing. This is how I learn to write better.
I’m going to finish my implementation, and it’ll be at my functions/ directory.
I haven’t finished it yet, and I haven’t touched Netlify Dev, but I’ll end my story here.
This one has become very long one, and I’m going to need editing.
I might write a story for creating a component just like this one.
Well, then until next journey.